Our challenge from last week was that the developers were complaining about a slow query in the Stack Overflow database that wasn’t as fast as they’d like.
|
1 |
select * from users where length(displayname) > 35; |
We have an index on DisplayName, but Postgres refuses to use that index in the execution plan, and it’s scanning the entire table instead:

Your Query Exercise challenge was to get that query to run dramatically faster, like under a second. An index on DisplayName doesn’t really help because the names are organized alphabetically, not by their length. (There is indeed an index on DisplayName on query.smartpostgres.com.)
Solution 1: Functional Indexes
Fortunately, Postgres has functional indexes, which let us index the data by the output of a function, like this:
|
1 |
create index users_length_displayname on users(length(displayname)); |
Then, when we run our query, the query plan shows… the same thing. Postgres doesn’t appear to have used the index.

Hmm, that’s a bummer. I was surprised Postgres didn’t automatically use the index, so I asked a question on DBA.se. It turns out that Postgres doesn’t automatically update statistics for newly created indexes. The clue was that Postgres estimated 7,202,721 rows – which just so happens to be exactly 33.33% of the number of rows in the table.
After running analyze, we get a nice, tidy fast plan:

Which I find kinda funny because now we have an estimate error in the other direction, hahaha, but at least Postgres decided to use the index.
Solution 2: Partial Indexes
Another option is partial indexes that hold just the portion of the table that matches our where clause filter:
|
1 2 |
create index users_long_displaynames on users(displayname) where length(displayname) > 35; |
That also runs quickly, as the query plan shows:
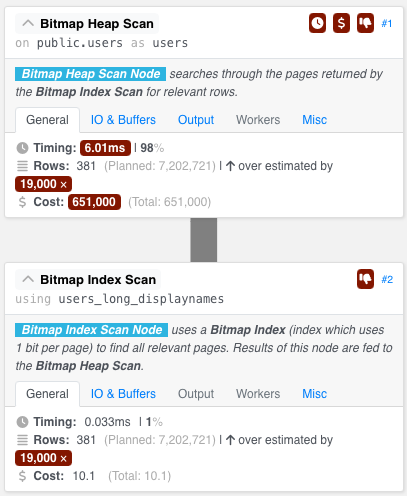
From 5-10 seconds, down to 5-10 milliseconds – that’s awesome.
Which Solution is Best?
Both indexes have a drawback: they slow down insert/update/deletes.
However, the partial index has less of a hit because we only have to maintain it when we insert/update/delete rows that match the partial index’s predicate – in this case, length > 35. Very few rows match that filter, so this index is effectively free.
If that length parameter varied, like if we sometimes searched for 1 or 15 or 35, then the partial index wouldn’t help as much, and the function index would make more sense. And of course, we could combine the techniques by doing a partial index on only a subset of the rows, and index their lengths as well.