Your challenge for this week was to improve estimation on a query. Stack Overflow has a dashboard that shows the top-ranking users in their most popular location. The Stack Overflow database even has an index to support it:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE INDEX users_location_displayname ON users(location, displayname); with toplocation as ( select location from users where location <> '' group by location order by count(*) desc limit 1 ) select u.* from toplocation inner join users u on toplocation.location = u.location order by u.reputation desc limit 200; |
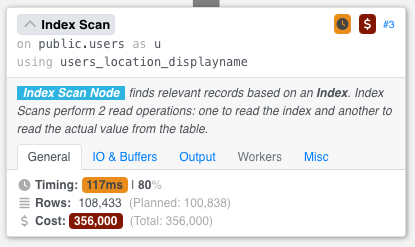
But the problem we were having was that the query took several seconds to run, and the query plan had tons of estimation problems. For example, when you hovered your mouse over that index scan operator, Postgres only guessed that 1,174 rows would come out from our most popular location – when in reality, 108,433 came out:

The Core of the Problem
The main problem is that when we run a statement (like select), Postgres:
- Designs the execution plan for the entire statement all at once, without executing anything, then
- Executes the entire statement all at once, with no plan changes allowed
Think of it as two different departments, neither of which are allowed to do the job of the other. The design department sketches out the query plan, but it has no idea of what this part of the query will produce:
|
1 2 3 4 5 6 7 8 |
with toplocation as ( select location from users where location <> '' group by location order by count(*) desc limit 1 ) |
Just for reference, the top location happens to be India.
The Core of the Solution
If the problem is that the database server:
- Designs the execution plan for the entire statement all at once, without executing anything, then
- Executes the entire statement all at once, with no plan changes allowed
Then the solution is to break the statement up into multiple statements. In pseudocode:
- Find the top location, then
- Find the users who live in that location, after we know what the location is
Because if I run the second query with India directly specified in the query:
|
1 2 3 4 5 |
select u.* from users u where u.location = 'India' order by u.reputation desc limit 200; |
Then the execution plan has much more accurate estimates:

Weirdly, the sort operation is now complaining about OVERestimation, hahaha:

In my example, I broke the second query up into a separate one with a hard-coded India value. That kind of thing is more easily done on the client side.
If you try to do it with a temporary function, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE FUNCTION pg_temp.get_users_by_location(parm_location varchar) RETURNS setof users AS $$ select u.* from users u where u.location = parm_location order by u.reputation desc limit 200 $$ LANGUAGE sql IMMUTABLE; with toplocation as ( select location from users where location <> '' group by location order by count(*) desc limit 1 ) select u.* from toplocation join pg_temp.get_users_by_location(toplocation.location) u on 1 = 1 order by u.reputation desc limit 200; |
Then we’re still facing the same problem of the single-statement optimization. The WITH query is optimized all at once, including the function’s contents. The explain plan has the same bad estimation on the number of people who live in the top location.
On the other hand, if you call the temporary function with the input value clearly defined:
|
1 |
select * from pg_temp.get_users_by_location('India') |
Then the plan’s estimations are bang on, and fast:
Another approach – if you try to do it entirely in Postgres with a temp table, like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DROP TABLE IF EXISTS toplocation; CREATE TEMPORARY TABLE toplocation AS select location from users where location <> '' group by location order by count(*) desc limit 1; select u.* from toplocation inner join users u on toplocation.location = u.location order by u.reputation desc limit 200; |
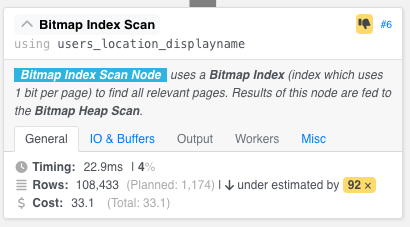
It doesn’t work because the explain plan shows the same wild under-estimation:
(sigh) Bummer!