In last week’s Query Exercise, I asked you why updating a table reduced its index sizes. Our table had a date column called last_update_date, and when we set that date on about 25% of the rows, then vacuumed the table, we noticed that the size of the index on last_update_date got smaller.
The key (no pun intended) is in the values we used to originally populate the last_updated_date column:
|
1 |
NOW() - (random() * interval '1 year') AS last_updated_date |
Check out the contents of the last_updated_date column:

They’re all relatively unique. Uniqueness isn’t guaranteed here, but as you can see, it’s pretty doggone unique. So, let’s think about the contents of an index on last_access_date – it would look like this:
|
1 2 3 4 |
select last_updated_date, ctid from recipes order by last_updated_date limit 100; |
The results visualize the contents of the index:

The index will really have each last_updated_date along with its matching ctids. A true visualization would show that first last_updated_date (22.543), followed by its two ctids (10403,81 and 10403,82).
The last_updated_dates aren’t completely unique – there are some duplicates, but a lot of the values are distinct. We can count how many distinct last_updated_dates there are:
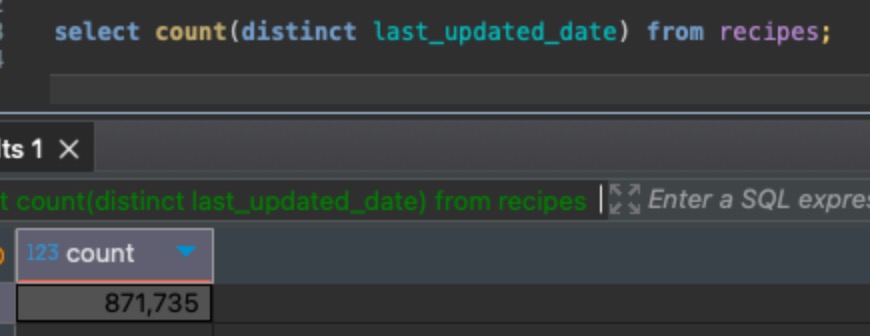
Then, when our update runs, it sets about 25% of the rows to have the same last_updated_date:
|
1 2 3 4 |
update recipes set cuisine = 'Jeju', last_updated_date = NOW() where recipe_id % 4 = 0; |
Which means there are way less distinct last_updated_dates after the update:
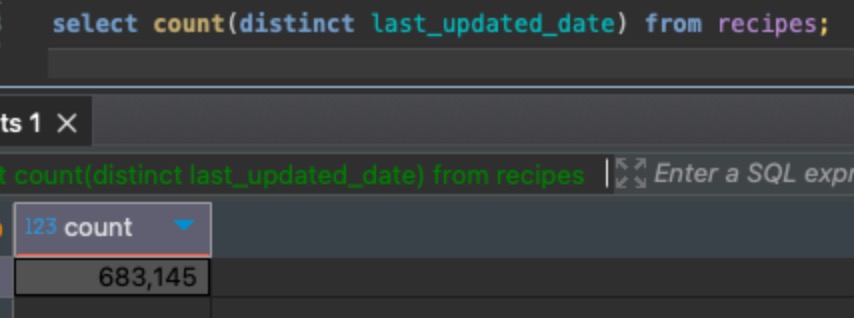
When a single last_updated_date has a lot of matching rows (ctids), then Postgres is able to compress that index because it only has to store that last_updated_date once, followed by the list of ctids that match that last_updated_date.
To see an extreme version of that, let’s set all of the rows to have exactly the same last_updated_date, then vacuum the table and check the size of the index:
|
1 2 3 4 5 6 7 |
update recipes set last_updated_date = NOW(); /* Compact it and check the size of the index: */ vacuum full recipes; select pg_relation_size('recipes_last_updated_date'); |
The results:

The index drops from 22MB, to 18MB, all the way down to 7MB when all the rows in the index have the same value.
The takeaway: the more similar a column’s content is, the smaller indexes will be on that column. The more unique a column’s values are, the larger its indexes will become.
I found this really interesting because Microsoft SQL Server does not share that same behavior! In SQL Server, a b-tree index’s size is the same whether all the values are unique or all identical.
2 Comments. Leave new
Really interesting post. I appreciate these as I am new to PostgreSQL. I did want to give you a heads-up that the link to the blog post on SQL Server’s indexing behavior seems to be broken.
Glad you liked it! I just fixed the link to the SQL Server post – good catch!